 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabPrep: Closing the Feature Engineering Gap in Tabular Benchmarks
Jun 01, 2026Progress in tabular machine learning has largely focused on increasingly sophisticated model architectures. At the same time, feature engineering remains a critical yet underexplored component of real-world modeling pipelines that is entirely absent from modern benchmarks, which creates an unquantified evaluation gap. In this work, we introduce TabPrep, a lightweight preprocessing pipeline composed of feature generators that are carefully designed to target three specific structural data patterns. We show that many widely used model classes exhibit predictable blind spots to these patterns and that systematic feature engineering alone can establish new peak performance. Across the TabArena benchmark, integrating TabPrep into model training and tuning consistently improves performance for tree-based, neural, linear, and foundation models, often surpassing gains achieved by model-centric innovations alone. TabPrep outperforms previous automated feature engineering approaches in performance, efficiency, and applicability across datasets, enabling integration into large-scale benchmarks. By releasing TabPrep (see https://github.com/atschalz/tabprep), we enable researchers to integrate feature engineering into their benchmarking setup, filling a longstanding gap in tabular evaluations.
TabPFN-3: Technical Report
May 13, 2026Tabular data underpins most high-value prediction problems in science and industry, and TabPFN has driven the foundation model revolution for this modality. Designed with feedback from our users, TabPFN-3 builds on this foundation to scale state-of-the-art performance to datasets with 1M training rows and substantially reduce training and inference time. Pretrained exclusively on synthetic data from our prior, TabPFN-3 dramatically pushes the frontier of tabular prediction and brings substantial gains on time series, relational, and tabular-text data. On the standard tabular benchmark TabArena, a forward pass of TabPFN-3 outperforms all other models, including tuned and ensembled baselines, by a significant margin, and pareto-dominates the speed/performance frontier. On more diverse datasets, TabPFN-3 ranks first on datasets with many classes, and beats 8-hour-tuned gradient-boosted-tree baselines on datasets up to 1M training rows and 200 features. TabPFN-3 introduces test-time compute scaling to tabular foundation models. Our API offering TabPFN-3-Plus (Thinking) exploits this to beat all non-TabPFN models by over 200 Elo on TabArena, rising to 420 Elo on the largest data subset, and outperforms AutoGluon 1.5 extreme while being 10x faster, without using LLMs, real data, internet search or any other model besides TabPFN. TabPFN-3 extends the capabilities of our models, enabling SOTA prediction on relational data (new SOTA foundation model on RelBenchV1) and tabular-text data (SOTA on TabSTAR via TabPFN-3-Plus); and improves existing integrations: a specialized checkpoint, TabPFN-TS-3, ranks 2nd on the time-series benchmark fev-bench, and SHAP-value computation is up to 120x faster. TabPFN-3 achieves this performance while being up to 20x faster than TabPFN-2.5. In addition, a reduced KV cache and row-chunking scale to 1M rows on one H100 with fast inference speed.
Multi-layer Stack Ensembles for Time Series Forecasting
Nov 19, 2025Ensembling is a powerful technique for improving the accuracy of machine learning models, with methods like stacking achieving strong results in tabular tasks. In time series forecasting, however, ensemble methods remain underutilized, with simple linear combinations still considered state-of-the-art. In this paper, we systematically explore ensembling strategies for time series forecasting. We evaluate 33 ensemble models -- both existing and novel -- across 50 real-world datasets. Our results show that stacking consistently improves accuracy, though no single stacker performs best across all tasks. To address this, we propose a multi-layer stacking framework for time series forecasting, an approach that combines the strengths of different stacker models. We demonstrate that this method consistently provides superior accuracy across diverse forecasting scenarios. Our findings highlight the potential of stacking-based methods to improve AutoML systems for time series forecasting.
fev-bench: A Realistic Benchmark for Time Series Forecasting
Sep 30, 2025Benchmark quality is critical for meaningful evaluation and sustained progress in time series forecasting, particularly given the recent rise of pretrained models. Existing benchmarks often have narrow domain coverage or overlook important real-world settings, such as tasks with covariates. Additionally, their aggregation procedures often lack statistical rigor, making it unclear whether observed performance differences reflect true improvements or random variation. Many benchmarks also fail to provide infrastructure for consistent evaluation or are too rigid to integrate into existing pipelines. To address these gaps, we propose fev-bench, a benchmark comprising 100 forecasting tasks across seven domains, including 46 tasks with covariates. Supporting the benchmark, we introduce fev, a lightweight Python library for benchmarking forecasting models that emphasizes reproducibility and seamless integration with existing workflows. Usingfev, fev-bench employs principled aggregation methods with bootstrapped confidence intervals to report model performance along two complementary dimensions: win rates and skill scores. We report results on fev-bench for various pretrained, statistical and baseline models, and identify promising directions for future research.
MLZero: A Multi-Agent System for End-to-end Machine Learning Automation
May 20, 2025Existing AutoML systems have advanced the automation of machine learning (ML); however, they still require substantial manual configuration and expert input, particularly when handling multimodal data. We introduce MLZero, a novel multi-agent framework powered by Large Language Models (LLMs) that enables end-to-end ML automation across diverse data modalities with minimal human intervention. A cognitive perception module is first employed, transforming raw multimodal inputs into perceptual context that effectively guides the subsequent workflow. To address key limitations of LLMs, such as hallucinated code generation and outdated API knowledge, we enhance the iterative code generation process with semantic and episodic memory. MLZero demonstrates superior performance on MLE-Bench Lite, outperforming all competitors in both success rate and solution quality, securing six gold medals. Additionally, when evaluated on our Multimodal AutoML Agent Benchmark, which includes 25 more challenging tasks spanning diverse data modalities, MLZero outperforms the competing methods by a large margin with a success rate of 0.92 (+263.6\%) and an average rank of 2.28. Our approach maintains its robust effectiveness even with a compact 8B LLM, outperforming full-size systems from existing solutions.
TabRepo: A Large Scale Repository of Tabular Model Evaluations and its AutoML Applications
Nov 06, 2023We introduce TabRepo, a new dataset of tabular model evaluations and predictions. TabRepo contains the predictions and metrics of 1206 models evaluated on 200 regression and classification datasets. We illustrate the benefit of our datasets in multiple ways. First, we show that it allows to perform analysis such as comparing Hyperparameter Optimization against current AutoML systems while also considering ensembling at no cost by using precomputed model predictions. Second, we show that our dataset can be readily leveraged to perform transfer-learning. In particular, we show that applying standard transfer-learning techniques allows to outperform current state-of-the-art tabular systems in accuracy, runtime and latency.
AutoGluon-TimeSeries: AutoML for Probabilistic Time Series Forecasting
Aug 10, 2023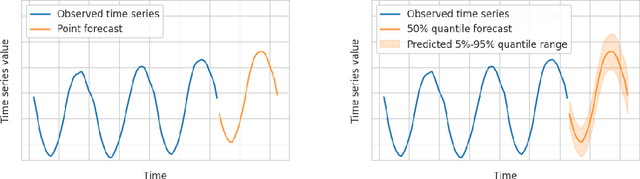
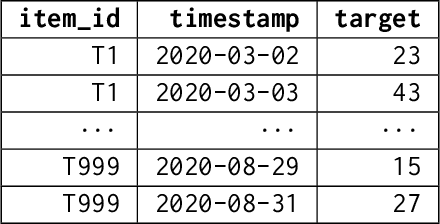
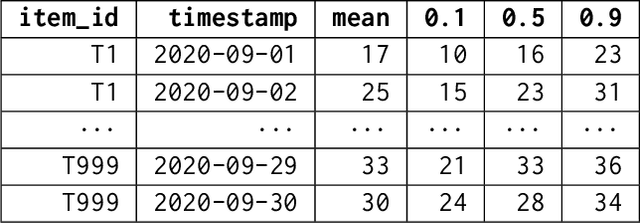
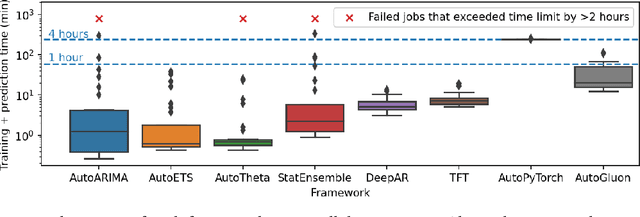
We introduce AutoGluon-TimeSeries - an open-source AutoML library for probabilistic time series forecasting. Focused on ease of use and robustness, AutoGluon-TimeSeries enables users to generate accurate point and quantile forecasts with just 3 lines of Python code. Built on the design philosophy of AutoGluon, AutoGluon-TimeSeries leverages ensembles of diverse forecasting models to deliver high accuracy within a short training time. AutoGluon-TimeSeries combines both conventional statistical models, machine-learning based forecasting approaches, and ensembling techniques. In our evaluation on 29 benchmark datasets, AutoGluon-TimeSeries demonstrates strong empirical performance, outperforming a range of forecasting methods in terms of both point and quantile forecast accuracy, and often even improving upon the best-in-hindsight combination of prior methods.
XTab: Cross-table Pretraining for Tabular Transformers
May 10, 2023



The success of self-supervised learning in computer vision and natural language processing has motivated pretraining methods on tabular data. However, most existing tabular self-supervised learning models fail to leverage information across multiple data tables and cannot generalize to new tables. In this work, we introduce XTab, a framework for cross-table pretraining of tabular transformers on datasets from various domains. We address the challenge of inconsistent column types and quantities among tables by utilizing independent featurizers and using federated learning to pretrain the shared component. Tested on 84 tabular prediction tasks from the OpenML-AutoML Benchmark (AMLB), we show that (1) XTab consistently boosts the generalizability, learning speed, and performance of multiple tabular transformers, (2) by pretraining FT-Transformer via XTab, we achieve superior performance than other state-of-the-art tabular deep learning models on various tasks such as regression, binary, and multiclass classification.
RLSbench: Domain Adaptation Under Relaxed Label Shift
Feb 06, 2023



Despite the emergence of principled methods for domain adaptation under label shift, the sensitivity of these methods for minor shifts in the class conditional distributions remains precariously under explored. Meanwhile, popular deep domain adaptation heuristics tend to falter when faced with shifts in label proportions. While several papers attempt to adapt these heuristics to accommodate shifts in label proportions, inconsistencies in evaluation criteria, datasets, and baselines, make it hard to assess the state of the art. In this paper, we introduce RLSbench, a large-scale relaxed label shift benchmark, consisting of >500 distribution shift pairs that draw on 14 datasets across vision, tabular, and language modalities and compose them with varying label proportions. First, we evaluate 13 popular domain adaptation methods, demonstrating more widespread failures under label proportion shifts than were previously known. Next, we develop an effective two-step meta-algorithm that is compatible with most deep domain adaptation heuristics: (i) pseudo-balance the data at each epoch; and (ii) adjust the final classifier with (an estimate of) target label distribution. The meta-algorithm improves existing domain adaptation heuristics often by 2--10\% accuracy points under extreme label proportion shifts and has little (i.e., <0.5\%) effect when label proportions do not shift. We hope that these findings and the availability of RLSbench will encourage researchers to rigorously evaluate proposed methods in relaxed label shift settings. Code is publicly available at https://github.com/acmi-lab/RLSbench.
Benchmarking Multimodal AutoML for Tabular Data with Text Fields
Nov 04, 2021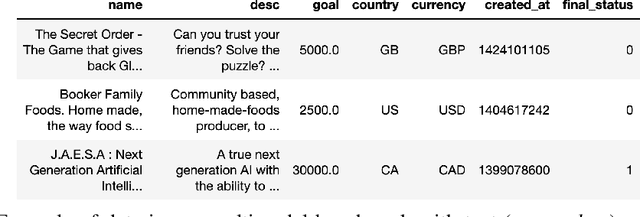
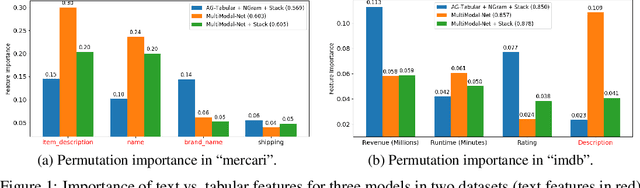
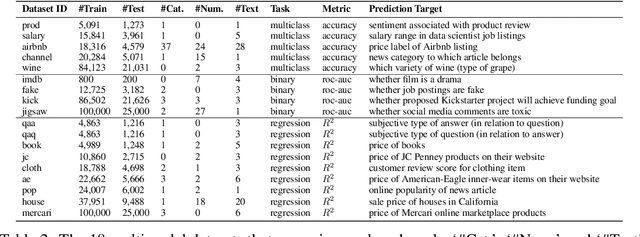
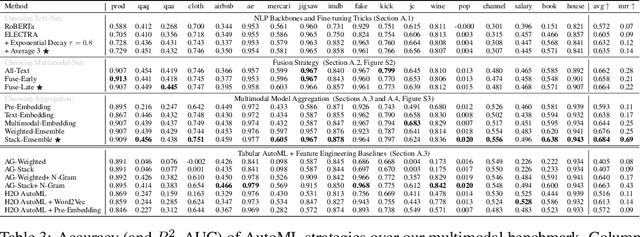
We consider the use of automated supervised learning systems for data tables that not only contain numeric/categorical columns, but one or more text fields as well. Here we assemble 18 multimodal data tables that each contain some text fields and stem from a real business application. Our publicly-available benchmark enables researchers to comprehensively evaluate their own methods for supervised learning with numeric, categorical, and text features. To ensure that any single modeling strategy which performs well over all 18 datasets will serve as a practical foundation for multimodal text/tabular AutoML, the diverse datasets in our benchmark vary greatly in: sample size, problem types (a mix of classification and regression tasks), number of features (with the number of text columns ranging from 1 to 28 between datasets), as well as how the predictive signal is decomposed between text vs. numeric/categorical features (and predictive interactions thereof). Over this benchmark, we evaluate various straightforward pipelines to model such data, including standard two-stage approaches where NLP is used to featurize the text such that AutoML for tabular data can then be applied. Compared with human data science teams, the fully automated methodology that performed best on our benchmark (stack ensembling a multimodal Transformer with various tree models) also manages to rank 1st place when fit to the raw text/tabular data in two MachineHack prediction competitions and 2nd place (out of 2380 teams) in Kaggle's Mercari Price Suggestion Challenge.